Simple React for small apps - the "funnel architecture"
A note on terminology
The term “app” is used when I’m talking about the kind of web-based Single Page Applications I usually work on. The intent is to distinguish my target context from other popular types of development - c.f. “web sites”, “mobile applications” and “desktop applications”.
Introduction to the Cabbage application
Cabbage is not a real application - it’s an example I implemented to learn about Supabase , and to serve as a full-fat SSCCE for the Simple React article series.
In terms of functionality, Cabbage doesn't do anything at all other than allow you to log in and configure some user-specific details.
Funnel architecture
By “funnel architecture”, I mean the idea of concentrating as many as possible of the high-level design concepts of your app into a single file, structured via the React component hierarchy.
export function App(){
return <MuiThemeProvider theme={theme}>
<CssBaseline/>
<ReactErrorBoundary>
<ErrorDialogProvider>
<NavigationProvider>
<SupabaseProvider>
<AuthenticatedUserProvider>
<AppNavBar/>
<UserScreen/>
<OtherScreen/>
<ScratchScreen/>
</AuthenticatedUserProvider>
</SupabaseProvider>
</NavigationProvider>
</ErrorDialogProvider>
</ReactErrorBoundary>
</MuiThemeProvider>;
}
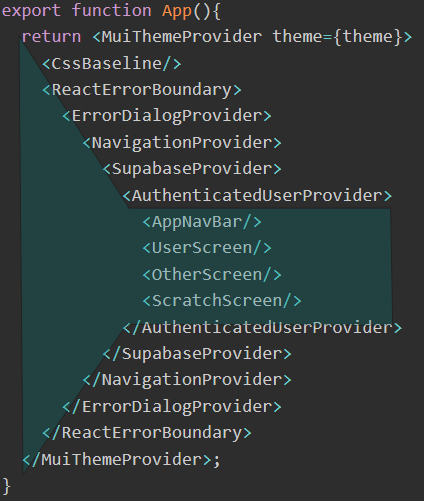
The Funnel structure
The outer edges or “lip” of the funnel tends to contain bootstrap infrastructure (such as theming, CSS baseline, etc.) and edge-case handling like dealing with runtime errors, unauthenticated users, etc.
As you get closer to the "spout" of the funnel, you see the happy-day use-cases of the app - the ordinary pages/screens being used by fully authenticated/authorized users.
Features of the funnel architecture
- serve as an “index” of infrastructural and functional concepts that a developer new to the app will eventually need to understand
- enumerate and distinguish “infrastructure” components (“edges”/“lip” of the funnel)
- indicate the “dependency order” for infrastructure components
- enumerate and distinguish functional areas of the app (“spout” of the funnel)
Where should the funnel live?
For a create-react-app project like Cabbage, the App component is the obvious place to put the “funnel”. I think it’s better to let the index file serve as a bootstrap area for the app.
The funnel as documentation
Most applications have a readme file in the root of the application. Readme files usually talk about the purpose of the project and how to build it, but they don’t often go deeper into the structure of the application (and really shouldn’t - keep your project readme focused on the project itself, not implementation details). The “funnel architecture” component can be linked directly from the project readme or perhaps one/two clicks deeper, e.g. in the readme for the “front end” tier, if that’s how your project is structured.
The funnel serves as a good place to start when developers move past the on-boarding phase (having questions such as “what's this for?” and “how do I build this?”) into the I-have-work-to-do stage (with questions like “where’s the X functionality?” and “how does authentication work?”).
It takes work to keep the architectural funnel “clean” enough that it can be read at a glance and be helpful to new developers. Bits of disorganised infrastructure and other technical debt will naturally accumulate into the funnel component - it’s worth the effort to maintain. Use all that time you saved not having to write and maintain that architecture section of your on-boarding documentation (Ha HA, right?)
About infrastructure components
All apps need infrastructure components. Some refer to it as “middleware”, though I think that term is better reserved for “middleware libraries/frameworks” like Redux, React-router, API middleware, etc. Those kinds of library middleware are often overkill for a small to medium-sized applications - but even trivial applications need at least a little bit of infrastructure.
How the infrastructure components relate to and interact with each other, and how your infrastructure relates to and interacts with all the “normal” functionality - that’s the architecture of your app.
The edges of the funnel - defining infrastructure component dependencies
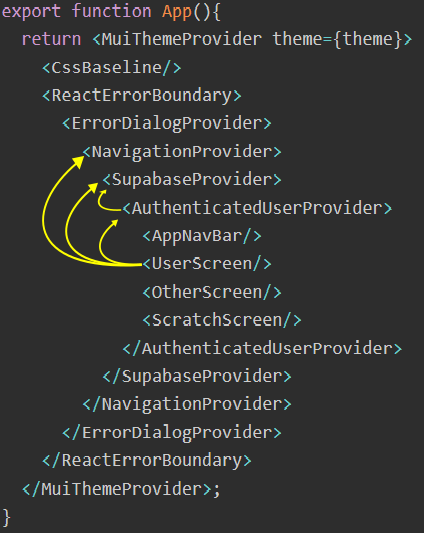
Components that are lower in the spout depend on functionality defined higher in the spout, but not the other way round. So the SupabaseProvider can rely on the NavigationState provided by the NavigationProvider but the ReactErrorBoundary component has to be written carefully, because none of the other components will be available.
For a funnel architecture, this structure is enforced by the nature of the React component hierarchy - but it’s crucial to have a strict order of dependence to your infrastructure components regardless. If you have unknown/uncontrolled dependency cycles in your infrastructure, your architecture quickly becomes confused and fragile - and then you’re in for a very bad time when things change.
The spout of the funnel - normal functionality
The spout of the funnel enumerates all the “normal” functionality of the app. Cabbage uses a “pull-routing” model, so the spout is just a simple list of the “Screen” components of the app.
The screens are written in the simple “happy-day” style - they expect that, by the time they are rendered, all the infrastructure components will have already done their work. That is, the author of a screen component can presume all edge-cases (errors, unauthenticated users, etc.) have already been handled. All data/functionality from infrastructure components is expected to available via React use hooks.
Does it scale to “large” applications?
I don’t know - but I doubt it.
I use the funnel architecture for Kopi - since orignially re-structuring to the funnel architecture, Kopi has grown from about 10 screens to more than 25 (which I’d consider somewhere between “trivial” and “small”).
Kopi is currently a “side-project” for me - sometimes I can go a month or more without working on the front-end specifically. The funnel architecture helps me re-familiarize and get going again very quickly when I’m come back to it after a hiatus. That’s in contrast with the back-end of Kopi, which is based on Spring - re-familiarising myself with the back-end architecture usually takes longer and there’s no single place to go to in the code to get a birds-eye view.
I don’t expect that I would have any problems with this architecture scaling up to 50 or even 100 screens. I think you’d have to work hard to scale it to 1000 screens worth of functionality though and you’d definitely want to have a plan for a better architecture by the time you got to that size.
But that's how architecture design works - design to handle one order of magnitude of growth easily and be able to stretch to two. More than that is a waste - I can't even imagine a future where the Kopi app would need to scale to 1000 screens. I'd split it into multiple apps long before it reached that size.
So, in summary; I’d say the funnel architecture would scale up to “medium” sized apps - but not “large” or “huge” applications.
Dealing with architectural change
Architectural change is inevitable - apps are constantly under pressure. Application functionality grows. Requirements change. Your target market will shift and your user-base is growing (hopefully). And let’s not forget that the fundamental platform that is the web is slowly but constantly changing underneath you.
A clearly defined and structured set of infrastructure components allows you to have coherent conversations about how to adapt to your new requirements. Hopefully, you can come up with an incremental plan for change instead of falling back on the dreaded “architecture re-write”.
For small to medium sized apps, the funnel architecture gives you a single architectural concept that is easy to understand. Because the funnel is a concrete structure within your codebase, it’s always up-to-date. If you put the work in to keep it clean and clear - it’s relatively easy to communicate.
An example of architectural change
What if I decided Cabbage should use a popular identity service like Auth0 or Okta?
At the moment, Cabbage uses Supabase for authentication - so the AuthenticatedUserProvider relies on the SupabaseProvider.
That would have to change. We'd need to re-structure the infrastructure; likely split the AuthenticatedUserProvider into separate authentication and authorization components, sandwiching the SupabaseProvdider in between, etc.
These kinds of changes become much easier to talk about and plan out a structured approach when you have something concrete to point at.
Further Simple React articles
The “Simple React” article series is written to enumerate some ideas I’ve found useful when implementing small to mid-sized “apps” in React. Even though Cabbage doesn’t do anything much - it still has full-fledged implementations of the following ideas that I want to write about.
React specific Cabbage articles
- The “funnel architecture” for simple apps
- “Pull-routing” for simple apps
- Handling errors at multiple granularities
- Separation of Authentication from Authorization
- React Context as dependency injection
- Using the React component hierarchy to simplify component logic
Supabase specific Cabbage articles
- Generating types from Supabase
- Using Flyway to manage the Supabase schema
- Build pipelines and environment management with Supabase
If you have a preference for which you’d like to see first, or ideas for other articles - get in touch!
Please note: Kopi does not use Supabase. Kopi uses Postgres - but the database is hosted privately via AWS RDM. Supabase is a fantastic basis for something like Cabbage so that people can fork and get up and running their own instance of Cabbage quickly, but it wouldn’t be a good fit for Kopi (at least, not yet).