Simple React: Capturing client errors
Why capture errors?
Even the simplest apps will have errors.
Users are often unable or unwilling to tell you something is wrong. They'll either work around the problem while silently judging you - or they'll just stop using your app.
One good way to deal with errors is to do the reporting for your users. Why make your users do a job your app could be doing?
A note on data privacy
Be aware of data you might be collecting unintentionally, especially when using 3rd party libraries. This is particularly important when using libraries like Sentry that submit "breadcrumbs" along with error reports.
Automatically collecting the context of issues is a powerful tool for diagnosing problems - but like any power tool, it can be dangerous. If you (or your 3rd party libraries) are logging sensitive information to the console or leaking information in location URLs or anything else like that; then that data might accidentally be sent to the server as part of an error report.
Don't succumb to the temptation to collect data just in case it's needed. You don't need to protect what you didn't collect.
Why use Sentry?
Sentry is a paid service for capturing and managing software errors. Sentry does more than just capturing logging from browsers, it allows collecting information from many sources (mobile apps, web apps, server processes, etc.) and then collates and presents it all in a slick UI. You can even integrate the Sentry processing with your own issue tracking tools (or use the Sentry tooling) to track investigation and resolution of all these issues that your fancy new error capturing has told you about.
The Sentry client has logic for catching uncaught errors, debouncing event sending and collecting error context (console logs, network requests, etc.) - I don't want to write that stuff myself right now.
There's lots of tools similar to Sentry, but I chose their client because it's open source , popular and redirecting the event collection to a custom endpoint is well documented.
Why not use Sentry?
Because it's > 20KB, after compression . That's about 15% of the entire size of our example Cabbage app!
Why not use the Sentry React components?
I don't plan to stick with the Sentry library long term. I'd rather use a light-weight library that's focused on the job of capturing errors. Partly to save on size of the app (20KB!) and partly for peace-of-mind. Any suggestions?
Seeing it in action
If you want to see the error capturing sending events in a working app, load up the Cabbage error handling page and click any of the "cause error" buttons.
All the Sentry-specific code is contained in SendEventUtil , the intentional error logic is in the error handling screen code.
Using Supabase as the data sink
Instead of submitting errors to the Sentry data collection servers, which are blocked by uBlock anyway, we want to submit the errors to our own back-end. In this example, we're submitting the Sentry event data to a Postgres stored procedure that is published as a REST endpoint via Supabase.Redirecting Sentry error submission
Here's the code for having sentry submit to a custom endpoint.
export function initSendEvent(){
Sentry.init({
/* Sentry won't work if you don't give something that looks valid */
dsn: "https://1@example.com/1",
transport: SentrySupabaseTransport,
});
}
const storeUrl = `${Config.supabaseUrl}/rest/v1/rpc/${Functions.store_sentry_event}`;
class SentrySupabaseTransport extends Sentry.Transports.BaseTransport {
sendEvent(event: Event): PromiseLike<SentryResponse>{
return fetch(storeUrl, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'apikey': Config.supabaseAnonKey!,
},
body: JSON.stringify({json_content: event})
}).then((response) => {
…
});
}
}
Note that a real Sentry "Data Source Name" is not necessary, you don't even have to sign up to Sentry for this code to work.
Creating the Supabase data sink
The Cabbage backend uses Supabase to host a Postgres database that can be accessed via REST API endpoints. Flyway is used to manage schema migrations.
Here's the code to create the Postgres schema structures necessary to store the captured errors.
create schema if not exists private;
create table private.sentry_event (
id integer generated by default as identity
constraint sentry_event_pkey primary key,
received timestamp without time zone not null,
content json not null
);
grant insert, select, update, delete, truncate, references, trigger
on private.sentry_event to supabase_auth_admin;
grant insert on private.sentry_event to anon;
create or replace function public.store_sentry_event(json_content jsonb)
returns void security definer
language sql
as $$
insert into private.sentry_event (received, content)
values(transaction_timestamp(), json_content);
$$;
grant execute on function public.store_sentry_event(jsonb) to anon;
What's with the private Supabase schema?
In Supabase - the public schema is "open by default", other schema are "restricted by default".
Cabbage puts the event data in a table in a separate private schema where Supabase does not provide any access to it via the REST API. The name "private" is intended to communicate the need to be aware of visibility issues. We then create a stored procedure in the public schema that stores the data into the data table.
There is another way do this with Supabase - you could create the event storage table in the public schema then lock it down with row level security .
Why use a separate schema instead of relying on RLS?
Captured error events may accidentally contain sensitive information - access to sensitive data should definitely be restricted by default.
If you forget to add the stored procedure to store data into the table, then nobody can store the captured data. That's bad, but you'd notice it fairly quickly.
If you forget to add row level security to your table (or get the policies wrong), then anybody can access the data. That's worse, and without some other validation mechanism - much harder to notice.
Viewing the errors
Once the error reports start flowing, you're going to need to look at them.
As shown in the schema creation code, we store the Sentry event data as a document in a JSONB column - as opposed to modelling the event as a relational data structure.
Here's a SQL query to view the most recent errors, including joining the error report against the user table so you can see who is experiencing the error.
select
received "server time",
to_timestamp(cast(e.content ->> 'timestamp' as numeric)) "client time",
e.content -> 'user' ->> 'id' "user id",
u.email,
e.content ->> 'release' "release",
e.content "event"
from private.sentry_event as e
left join auth.users u on u.id::text = e.content -> 'user' ->> 'id'
order by e.id desc
limit 10
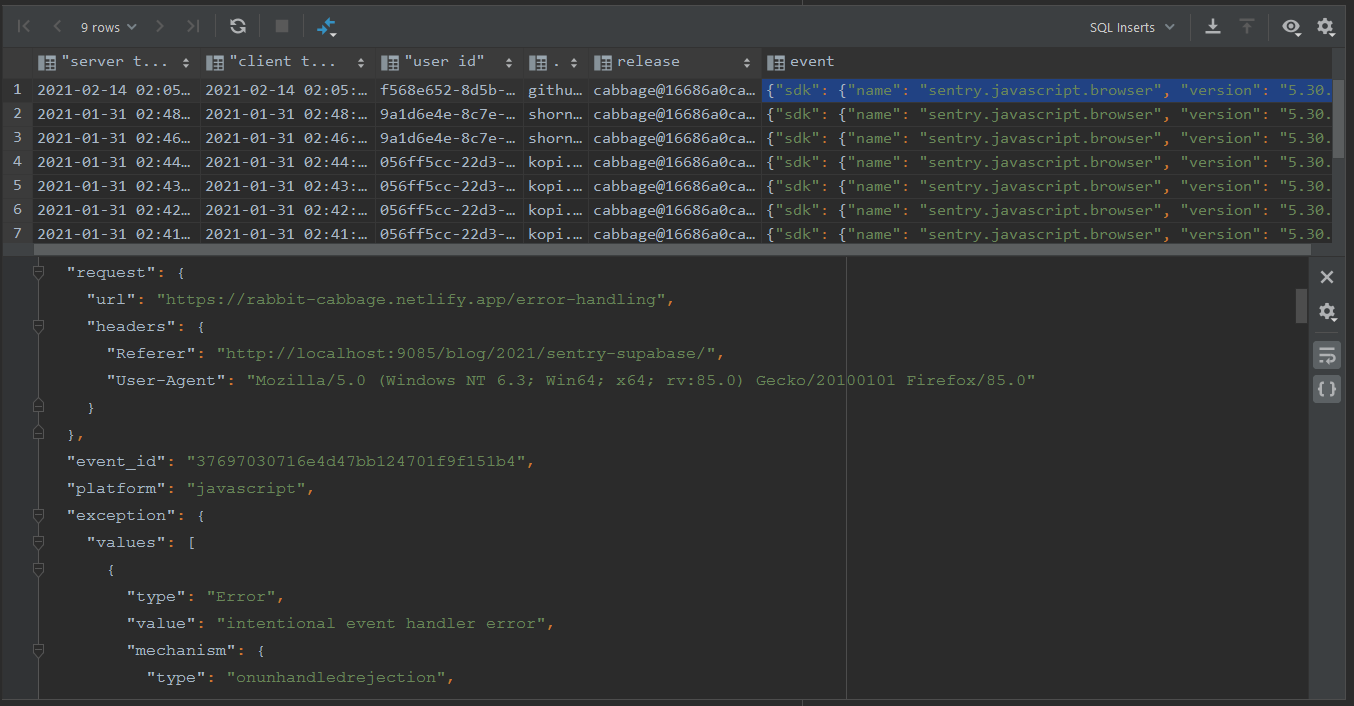
If you want to query the error data yourself - you'll need to follow the doco instructions to stand up your own copy of Cabbage, including your own Supabase project.
So why use a paid service at all?
Part of this article could be summarised as "how to use Sentry's stuff without giving them any money". So I thought I might explain why you might consider using a paid error capturing service like Sentry.
With the setup described in this article - you're left to write queries and troll through a bunch of JSON by hand in order to diagnose problems. You won't even know any errors occurred unless you go looking for them.
This is where services like Sentry start to earn their keep. They give you much nicer tools to inspect individual errors instead of manually analysing a blob of JSON.
That said, a UI to analyse individual errors is nice, but not worth the price of admission - in my opinion. The real value of paid services like Sentry is that they give you tools to aggregate and summarize all your errors. You can slice and dice your error data to look at it by time, by release, by browser etc. You can ask and answer questions like "was this error happening before the latest release?" or "is this problem only affecting Firefox users?"
Also, sticking tons of JSON documents in a relational DB, co-located with your real dataset like this might not be the best plan ever. Whoever operates your database will have a stern word or two for you when they find out what you're doing. "Why hello there, my friendly neighbourhood DBA - what's up with the baseball bat?"